This notebook introduces the concept of classes in Python and demonstrates their application in building a simple Perceptron, a pytorch neural network.
What are classes?
Classes in Python are like blueprints for creating objects. They let us bundle data (attributes) and functions (methods) together in a neat package. In the context of neural networks, we use classes to define models—like a Perceptron or an MLP—making our code organized and reusable.
Why use classes?
Structure: Classes help us organize related elements (e.g., weights, forward logic) together in one place.
Reusability: Once defined, we can create multiple instances (objects) of a class.
A class has: - An initiator method __init__ to set up initial attributes (like weights). - Other methods (like forward) to define what the class does.
Let’s see two examples: a simple Perceptron and a PyTorch-style network.
A simple perceptron
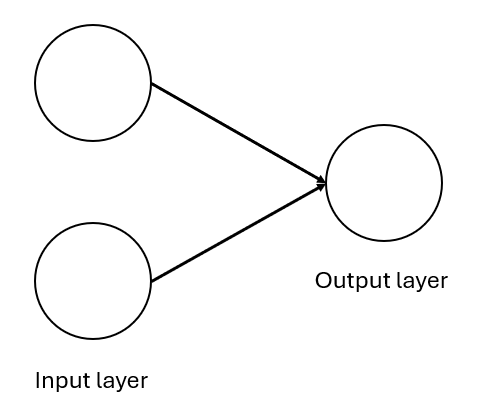
The Perceptron Class: This is like a tiny decision-maker. It sets up random “weights” and a “bias” when created.
The forward Method: It takes an input (like [1.0, 2.0]), mixes it with weights and bias, and decides “yes” (1) or “no” (-1) using a simple rule.
Testing It: We create a Perceptron, give it an input, and see what it says—super simple!
A perceptron with two neurons in the input layer connected to a single neuron on the output layer
import torchimport torch.nn as nnclass Perceptron:def__init__(self, input_size):# Initialize random weights and biasself.weights = torch.randn(input_size)self.bias = torch.randn(1)def forward(self, x): neuron_val = torch.dot(x, self.weights) +self.bias# If the neuron value is greater than 0, return 1; otherwise, return 0if neuron_val >0:return torch.tensor([1])else:return torch.tensor([0])# Test the Perceptronmy_perceptron = Perceptron(input_size=2) # Create an instance with 2 inputssample_input = torch.tensor([5.0, 2.0])output = my_perceptron.forward(sample_input)print("Perceptron output:", output)
Perceptron output: tensor([0])
A PyTorch neural network
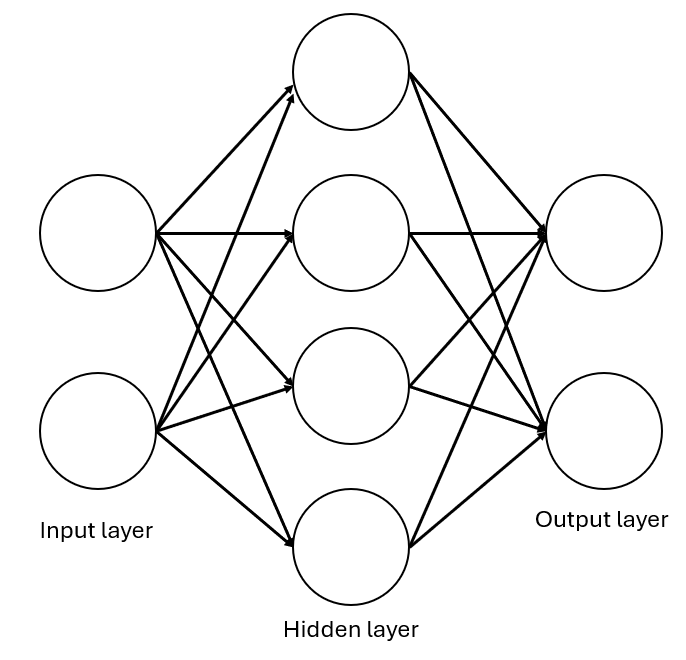
The SimpleNet Class: A simple neural network built with PyTorch. It sets up two “layers” of connections: one from inputs to a hidden layer (like a middle step), and another from the hidden layer to the output.
The forward Method: This tells the network how to process an input—it passes it through the first layer, adds a twist with ReLU, then goes through the second layer to get the final result.
Testing It: We create a SimpleNet, give it an input (like [1.0, 2.0]), and see what it predicts—nice and straightforward!
A multi-layer perceptron with two neurons on the input layer, connected to four neurons in a single hidden layer which are then all fully connected to two neurons in the output layer
class SimpleNet(nn.Module):def__init__(self, input_size, hidden_size, output_size):super(SimpleNet, self).__init__() # Initialize the parent nn.Module classself.layer1 = nn.Linear(input_size, hidden_size) # Input to hidden layerself.layer2 = nn.Linear(hidden_size, output_size) # Hidden to output layerself.relu = nn.ReLU()def forward(self, x):# Define the forward pass with ReLU activation x =self.layer1(x) x =self.relu(x) x =self.layer2(x)return xsample_input = torch.tensor([1.0, 2.0])# Test the SimpleNetmy_net = SimpleNet(input_size=2, hidden_size=4, output_size=2) # Create an instanceoutput = my_net(sample_input)print("SimpleNet output:", output)