# Remember to load the wine dataset again if you need to
from sklearn.datasets import load_wine
wine_data = load_wine()
X = wine_data.data
y = wine_data.target
feature_names = wine_data.feature_names
target_names = wine_data.target_namesOverfitting
When we get more a complex dataset, decision trees may introduce overfitting issues.
What is overfitting?
Overfitting happens when a machine learning model learns too much detail from the training data, including its noise and random fluctuations. Instead of capturing the general patterns, the model memorizes the data, which hurts its ability to make predictions on new, unseen data.
Imagine a student who memorizes all the answers from past exams, including the mistakes and irrelevant details, instead of understanding the core concepts. In practice, when the actual test has slightly different questions, the student struggles — because they focused too much on memorization rather than understanding.
Overfitting in decision trees
With decision trees, overfitting happens when the tree becomes too deep or too complex, trying to perfectly classify the training data by making splits for every little variation.
- Training accuracy becomes very high (because it memorizes the data)
- Testing accuracy drops (because it struggles with new data)
To understand the overfitting issue, let’s add some noises to the wine dataset.
import numpy as np
# Add noise: Gaussian noise (mean=0, std=feature_std * noise_factor)
noise_factor = 0.3
rng = np.random.RandomState(42)
X_noisy = X + noise_factor * rng.normal(size=X.shape)
# Add irrelevant random features
random_features = rng.normal(size=(X.shape[0], 5)) # add 5 random features
X_noisy = np.hstack([X, random_features])
X_noisy.shape(178, 18)Now repeat what we’ve done before…
from sklearn.model_selection import train_test_split
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X_noisy, y, test_size=0.2, random_state=42)
print(f"Training set shape: {X_train.shape}")
print(f"Testing set shape: {X_test.shape}")Training set shape: (142, 18)
Testing set shape: (36, 18)from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# Train Decision Trees with different depths and record accuracy
max_depth_range = range(1, 10)
train_accuracies = []
test_accuracies = []
for depth in max_depth_range:
clf = DecisionTreeClassifier(max_depth=depth, random_state=42)
clf.fit(X_train, y_train)
# Predict on training and testing data
train_pred = clf.predict(X_train)
test_pred = clf.predict(X_test)
# Accuracy scores
train_acc = accuracy_score(y_train, train_pred)
test_acc = accuracy_score(y_test, test_pred)
train_accuracies.append(train_acc)
test_accuracies.append(test_acc)import matplotlib.pyplot as plt
# Plot training vs testing accuracy
plt.figure(figsize=(8, 5))
plt.plot(max_depth_range, train_accuracies, label='Training Accuracy', marker='o')
plt.plot(max_depth_range, test_accuracies, label='Testing Accuracy', marker='s')
plt.xlabel('Max Depth of Decision Tree')
plt.ylabel('Accuracy')
plt.title('Training vs Testing Accuracy (with Noise)')
plt.legend()
plt.grid(True)
plt.show()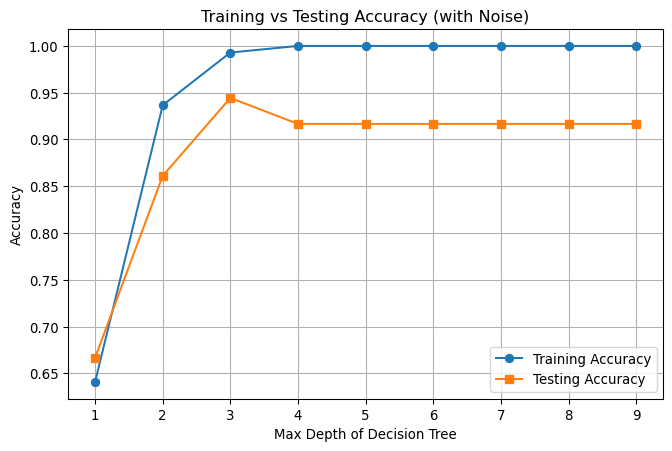
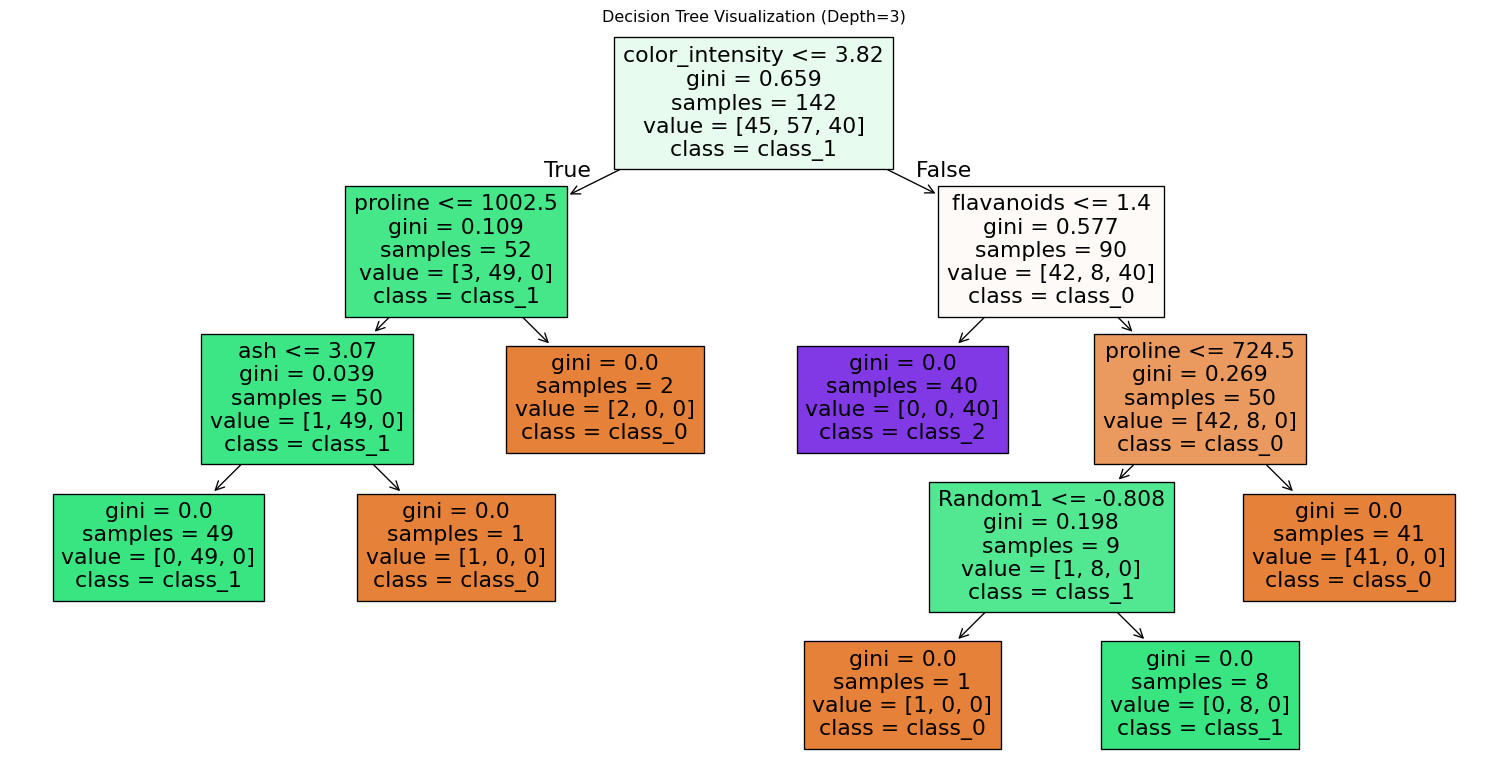
from sklearn.tree import plot_tree
clf_depth3 = DecisionTreeClassifier(max_depth=4, random_state=42)
clf_depth3.fit(X_train, y_train)
plt.figure(figsize=(20, 10))
plot_tree(clf_depth3, filled=True, feature_names=list(feature_names) + [f'Random{i}' for i in range(1, 6)], class_names=target_names)
plt.title('Decision Tree Visualization (Depth=3)')
plt.show()