Learn how to use scikit-learn to define a model and train it
Understand how to interpret the model parameters and coefficients
Trainer notes
Recommended time: 30 minutes
This section introduces model selection and training with linear regression.
Common issues: - Not being able to read the file because it is not in the same folder, or right folder. - Libraries (pandas, scikit-learn) not imported.
The process of extracting information from data using computers is called machine learning.
Machine learning a very large field and covers a whole host of techniques. In this course we will be discovering a few of them but let’s first start with the simplest form of machine learning, the linear fit or linear regression.
Please, remember to load your data as we did in previous sections:
Setting up our model
For this and for the other machine learning techniques in this course, we will be using scikit-learn. It provides a whole host of tools for studying data. You may also want to investigate statsmodels which also provides a large number of tools for statistical exploration.
scikit-learn provides a number of models which you can use to study your data. Each model is a Python class which can be imported and used. The usual process for using a model is:
Import the model you want to use
Create an instance of that model and set any hyperparameters you want
Fit the model to the data, this computes the parameters of the model using machine learning
Predict new information using the model
As we saw by plotting the data, the relationship between \(x\) and \(y\) is linear. In scitkit-learn, linear regression is available as scikit-learn.linear_model.LinearRegression.
We import the model and create an instance of it. By default the LinearRegression model will fit the y-intercept, but since we don’t want to make that assumption we explicitly pass fit_intercept=True. fit_intercept is an example of a hyperparameter, which are variables or options in a model which you set up-front rather than letting them be learned from the data.
from sklearn.linear_model import LinearRegressionmodel = LinearRegression(fit_intercept=True)model
LinearRegression()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
When running a Jupyter Notebook, you will see this model summary box appear every time a cell evaluates to the model itself. Here, writing model causes this to happen explicitly but it will happen any time the last line in a cell has the return value of the model too.
Fitting the data
Once we have created our model, we can fit it to the data by calling the fit() method on it. This takes two arguments:
The input data as a two-dimensional structure of the size \((N_{samples}, N_{features})\).
The labels or targets of the data as a one-dimensional data structure of size \((N_{samples})\).
In our case we only have one feature, \(x\), and 50 data points so it should be in the shape \((50, 1)\). If we just request data["x"] then that will be a 1D array (actually a pandas Series) of shape \((50)\) so we must request the data with data[["x"]] (which returns it as a single-column, but still two-dimensional, DataFrame). For a more thorough explanation of this dimensionality difference, see this explanation.
If you’re using pandas to store your data (as we are) then just remember that the first argument should be a DataFrame and the second should be a Series.
X = data[["x"]]y = data["y"]
model.fit(X, y)
LinearRegression()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
It is when you call this function that scikit-learn will go away and perform the machine learning algorithm. In our case it takes a fraction of a second but more complex models could take hours to compute.
By the time that this function returns, the model object will have had it’s internal parameters set as best the algorithm can do in order to predict \(y\) from \(x\).
We see the summary box appear here too as the fit method returns the model that it was called on, allowing you to chain together methods if you want.
Making predictions using the model
Once we’ve performed the fit, we can use it to predict the value of new data points which weren’t part of the original data set.
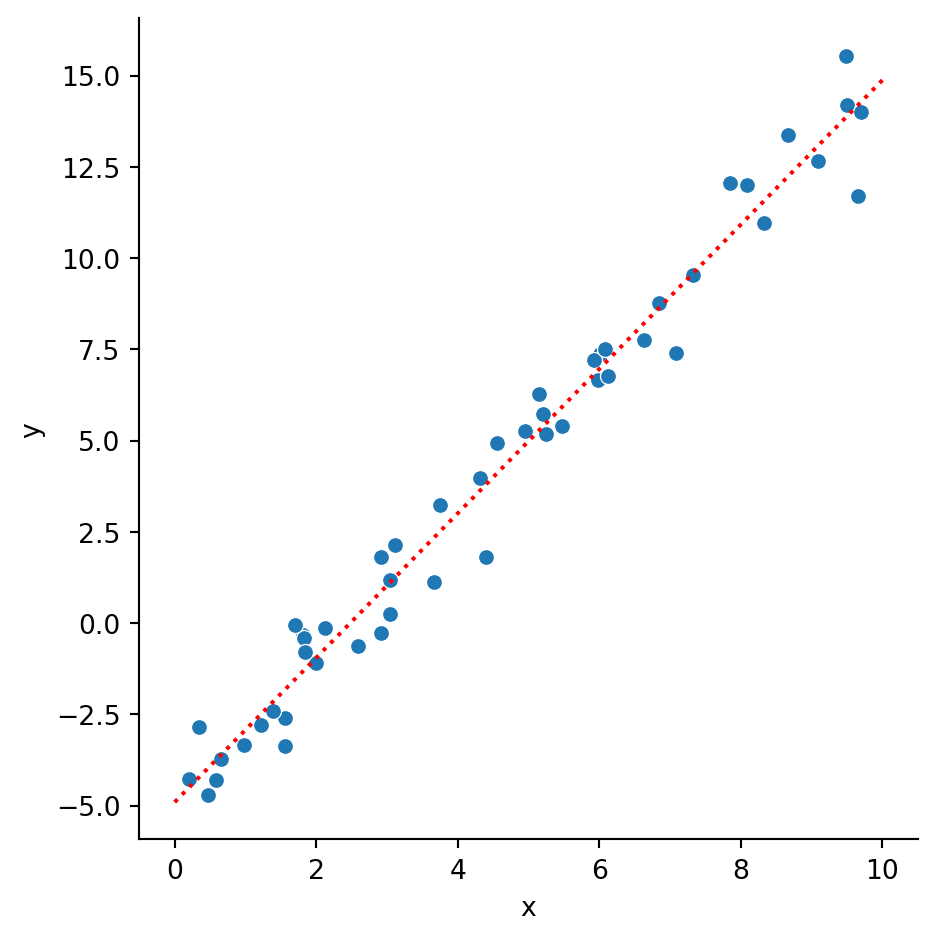
We can use this to plot the fit over the original data to compare the result. By getting the predicted \(y\) values for the minimum and maximum \(x\) values, we can plot a straight line between them to visualise the model.
The predict() function takes an array of the same shape as the original input data (\((N_{samples}, N_{features})\)) so we put our list of \(x\) values into a DataFrame before passing it to predict().
We then plot the original data in the same way as before and draw the prediction line in the same plot.
pred = pd.DataFrame({"x": [0, 10]}) # Make a new DataFrame containing the X valuespred["y"] = model.predict(pred) # Make a prediction and add that data into the tablepred
x
y
0
0
-4.903311
1
10
14.873255
import seaborn as snssns.relplot(data=data, x="x", y="y")sns.lineplot(data=pred, x="x", y="y", c="red", linestyle=":")
As well as plotting the line in a graph, we can also extract the calculated values of the gradient and y-intercept. The gradient is available as a list of values, model.coef_, one for each dimension or feature. The intercept is available as model.intercept_:
print(" Model gradient: ", model.coef_[0])print("Model intercept:", model.intercept_)
Model gradient: 1.9776566003853107
Model intercept: -4.903310725531115
The equation that we have extracted can therefore be represented as:
\[y = 1.97 x - 4.90\]
The original data was produced (with random wobble applied) from a straight line with gradient \(2\) and y-intercept of \(-5\). Our model has managed to predict values very close to the original.
Exercise
Run the above data reading and model fitting. Ensure that you get the same answer we got above.
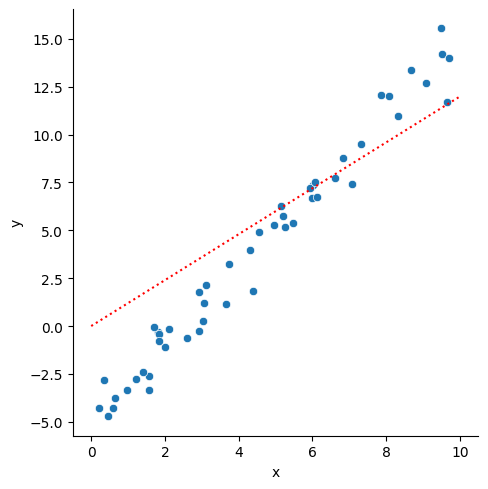
Try fitting without allowing the y-intercept to vary. How does it affect the prediction of the gradient?
Answer
import pandas as pddata = pd.read_csv("https://bristol-training.github.io/applied-data-analysis-in-python/data/linear.csv")
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression(fit_intercept=False)
pred = pd.DataFrame({"x": [0, 10]})pred["y"] = model.predict(pred)
import seaborn as snssns.relplot(data=data, x="x", y="y")sns.lineplot(data=pred, x="x", y="y", c="red", linestyle=":")
<Axes: xlabel='x', ylabel='y'>
print(" Model gradient: ", model.coef_[0])print("Model intercept:", model.intercept_)
Model gradient: 1.1985226874421444
Model intercept: 0.0